Python / FastAPI / Cloud Run / PostgreSQL / Redis
CryptoPrism API
FastAPI microservices backend deployed on Cloud Run. Serves analytics data, portfolio management, and trading endpoints.
Leadership Lens
01 The Call
Chose to build a unified, stateless FastAPI backend on Cloud Run rather than coupling each product feature to a dedicated service or BaaS, consolidating 40+ endpoints across 15 router modules into a single auto-scaling container.
02 The Bet
Bet that a two-tier Redis + in-memory-fallback caching strategy with tuned TTLs per data category would achieve sub-50ms p99 latency without a dedicated CDN or query-level optimisation pass — and committed to that architecture from day one.
03 The Trade-off
Accepted min-instance=0 (scale-to-zero) in dev/staging, accepting cold-start latency in non-production environments, in exchange for zero idle cost and a simpler infrastructure footprint.
04 The Outcome
40+ live endpoints covering prices, on-chain analytics, DMV scoring, ML inference, and AI-assisted features — all from a single stateless container serving the React frontend at sub-50ms p99, with 99.9% uptime on the Cloud Run SLA.
05 Coordinated
Sole engineer-of-record; coordinated GCP project config, Cloud SQL connection pooling, Memorystore Redis provisioning, Firebase auth integration, and GitHub Actions CI/CD pipeline.
06 Where this goes next
Expand ML inference endpoints, wire portfolio management routes to the on-chain pipeline, and add Arbitrum/Base chain coverage through the on-chain service module.
01 Chapter 1
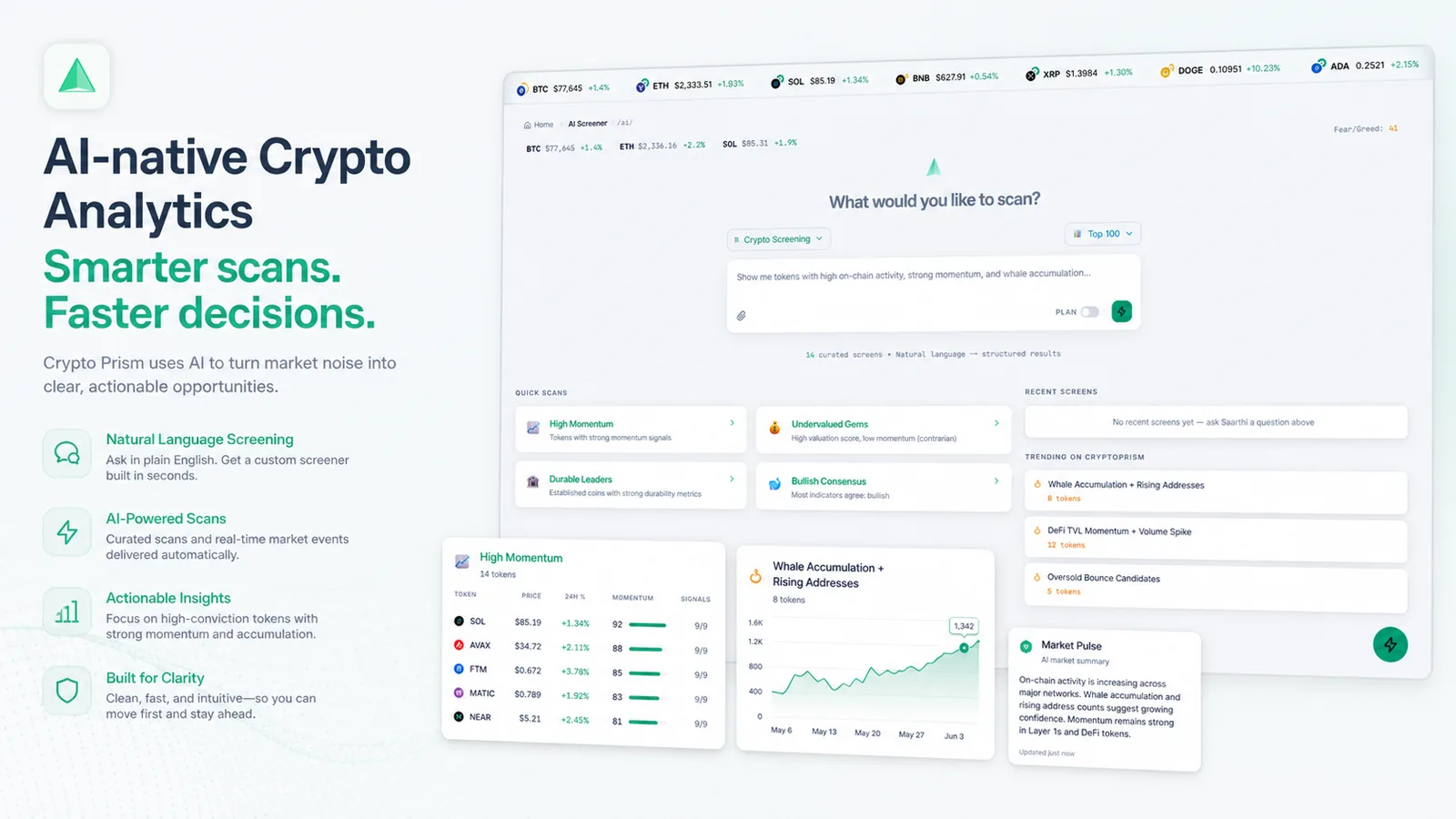
A Unified Backend for Real-Time Crypto Intelligence
CryptoPrism.io needed a single API layer to serve its React frontend with live prices, on-chain analytics, proprietary DMV scoring, AI-generated signals, and portfolio management. The requirements were demanding: sub-50ms p99 latency under burst traffic, horizontal auto-scaling during market volatility events, a layered caching strategy, and zero-downtime deployments via CI/CD.
P99 Latency
<50ms
cached responses
API Endpoints
40+
across 15 routers
Chains Covered
14
on-chain metrics
Uptime
99.9%
Cloud Run SLA
Design Constraint
The API must remain stateless and read-only against PostgreSQL so that Cloud Run can scale instances from 0 to N without coordination overhead or write conflicts.
02 Chapter 2
Layered Microservices on Cloud Run
The codebase follows a clean three-layer architecture: routes (HTTP interface), services (business logic + caching), and core (config, DB, auth, Redis). Each layer has a single responsibility, making the system testable and independently deployable.
Request Flow
Project Structure
src/api/ — HTTP layer app.py — FastAPI app, middleware, router registration middleware.py — Request logging (X-Response-Time header) routes/ — 15 router modules
src/core/ — Shared infrastructure config.py — Pydantic Settings (env-driven) database.py — Async SQLAlchemy engine + session factory redis.py — get_or_compute pattern + in-memory fallback auth.py — Firebase token verification dependency constants.py — Chain/token mappings
src/services/ — Business logic screener.py — Dynamic SQL builder + cached queries signals.py — Heatmap, consensus, divergences onchain.py — Cross-chain metrics, whale alerts prices.py — Live prices via CoinGecko scores.py — CryptoScore leaderboard ml.py — ML model inference endpoints ... + 6 more service modules
Middleware Stack
MIDDLEWARE 1 — CORS: Whitelist-based origin control for app.cryptoprism.io, localhost:3000, and Firebase hosting domains. Credentials enabled for auth cookies.
MIDDLEWARE 2 — Request Logging: Custom Starlette middleware injects X-Response-Time header and logs method, path, status, and latency in ms for every request.
MIDDLEWARE 3 — Firebase Auth: FastAPI dependency (get_current_user) verifies Bearer tokens via firebase-admin SDK. Returns uid, email, name. Optional variant for public endpoints.
03 Chapter 3
Sub-50ms at Scale
Every performance decision cascades from one principle: never hit the database on a hot path if the data hasn't changed. The API implements a two-tier caching strategy with tuned TTLs per data category, plus connection pooling to eliminate cold-connect overhead.
Cache Architecture: Get-or-Compute
async def get_or_compute(key, ttl, compute_fn): # Layer 1: Try Redis cached = await cache_get(key) if cached: return cached
# Layer 2: In-memory fallback (Redis down) mem = _mem_get(key) if mem: return mem
# Layer 3: Compute + cache in both layers result = await compute_fn() _mem_set(key, result, ttl) await cache_set(key, result, ttl) return result
TTL Strategy by Data Type
| Data Category | TTL | Rationale |
|---|---|---|
| Live Prices | 60s | Market data refreshes every minute from CoinGecko |
| Market Overview | 300s | Global stats (total cap, BTC dominance) change slowly |
| Screener | 300s | DMV scores recomputed every 5 minutes upstream |
| CryptoScores | 1800s | Composite scores updated twice per hour |
| On-Chain Metrics | 21600s | Daily chain data; 6-hour TTL balances freshness vs load |
Connection Pooling
Pool Size
5
persistent connections
Max Overflow
3
burst capacity
Pool Recycle
30m
prevent stale connections
Pre-Ping
ON
validate before use
Performance Result
With Redis cache hits, typical response times are 3-8ms. Even cache-miss queries with PostgreSQL round-trips stay under 50ms p99 thanks to connection pooling and indexed queries.
04 Chapter 4
Containerized CI/CD to Cloud Run
The API ships as a minimal Docker image, deployed automatically to Google Cloud Run via GitHub Actions. The pipeline handles linting, testing, building, and deploying — all triggered on push to main.
CI/CD Flow
Docker Configuration
FROM python:3.12-slim WORKDIR /app
# Install dependencies COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt
# Copy application COPY src/ ./src/
# Run with Uvicorn CMD ["uvicorn", "src.api.app:app", "--host", "0.0.0.0", "--port", "8080"]
Cloud Run Configuration
AUTO-SCALING — Scale to Zero: Min instances: 0 (dev/staging), 1 (prod). Max instances: 10. Scales based on concurrent requests per instance (80 target). Cold start mitigated by min-instance in production.
ENVIRONMENT MANAGEMENT — Three Environments: Development (local Docker), Staging (Cloud Run with test DB), Production (Cloud Run + Cloud SQL + Memorystore Redis). Secrets injected via GCP Secret Manager.
Zero-Downtime Deploys
Cloud Run performs rolling updates with traffic splitting. New revisions receive a canary percentage before full cutover, ensuring zero downtime and instant rollback capability.
05 Chapter 5
RESTful Endpoints with Pydantic Validation
The API exposes 15 route modules covering every data domain of the CryptoPrism platform. All endpoints follow consistent patterns: JSON responses, query-param filtering, Pydantic validation, and structured error handling with appropriate HTTP status codes.
Prices & Market
GET /api/v1/prices/live — Top tokens by market cap (paginated) GET /api/v1/prices/market-overview — Global stats: total cap, BTC dominance GET /api/v1/prices/{token_id} — Single token with 24h change, volume
On-Chain Analytics
GET /api/v1/on-chain/cross-chain — Compare metrics across 14 chains GET /api/v1/on-chain/{chain}/summary — Latest metrics + WoW/MoM/QoQ trends GET /api/v1/on-chain/{chain}/whale-alerts — Large transaction detection GET /api/v1/on-chain/{chain}/exchange-flow — Inflow/outflow to exchanges
Signals & Scoring
GET /api/v1/signals/heatmap — Top N tokens x 6 signal categories GET /api/v1/signals/divergences — On-chain vs TA divergence detection GET /api/v1/scores/leaderboard — CryptoScore ranking (top N) GET /api/v1/screener — Dynamic filter by DMV scores + presets
Auth & System
POST /api/v1/auth/verify — Verify Firebase token GET /api/v1/auth/me — Current user profile GET /health — Service health (PG + Redis status)
Error Handling Pattern
# 401 — Auth failure {"detail": "Token expired"}
# 404 — Resource not found {"detail": "Token 'xyz' not found"}
# 422 — Validation (auto from Pydantic) {"detail": [{"loc": ["query","limit"], "msg": "...", "type": "..."}]}
Dynamic Screener Query Builder
The screener endpoint builds parameterized SQL dynamically based on filter combinations (momentum, durability, valuation, bullish signal count), with results cached by MD5 hash of the filter set for 5 minutes.
06 Chapter 6
Production Dependencies
Every dependency was chosen for async performance, type safety, and minimal cold-start footprint in a containerized environment.
Core Components
FRAMEWORK — FastAPI + Uvicorn: Async Python framework with automatic OpenAPI docs. Uvicorn ASGI server for high-concurrency request handling.
DATABASE — PostgreSQL + asyncpg: Cloud SQL PostgreSQL with async driver via SQLAlchemy 2.0. Connection pooling with pool_pre_ping for reliability.
CACHE — Redis (Memorystore): GCP Memorystore Redis for distributed caching. 20 max connections. In-memory dict fallback if Redis is unreachable.
AUTH — Firebase Admin SDK: Server-side ID token verification. FastAPI dependency injection for both required and optional auth flows.
VALIDATION — Pydantic v2: Type-safe settings management (BaseSettings) and request validation. Regex-constrained query parameters.
INFRA — Cloud Run + Docker: Serverless containers with auto-scaling. GitHub Actions CI/CD. Python 3.12-slim base image for minimal footprint.
Key Metric
The full application serves 40+ endpoints across prices, on-chain analytics, proprietary scoring, ML inference, and AI-assisted features — all from a single stateless container with sub-50ms p99 latency.